동영상을 애니메이션 느낌 (혹은 다른 스타일 등)으로 변환하는 방법에는 크게 두 가지가 있다. 영상의 프레임을 모두 다 바꾼 후 이어붙이는 방법과 특정 키 프레임만 바꾼 후 EbSynth로 합성하는 방법이다.
1. 모든 프레임 변환 후 이어붙이기
해당 워크 플로우에 대한 여러 참고 자료를 확인해볼 수 있다.
- https://www.youtube.com/watch?v=kmT-z2lqEPQ
- https://www.reddit.com/r/StableDiffusion/comments/12i9qr7/i_transform_real_person_dancing_to_animation/
- https://www.youtube.com/@neilwong7760/about)
- https://www.reddit.com/r/StableDiffusion/comments/12l5kla/a_test_using_rotoscoped_footage_with_controlnet/
위 내용들을 정리하면 다음과 같다.
1. 원본 영상의 사이즈를 조절한다.
기본 사이즈인 512 * 512나 원하는 사이즈로 맞출 수 있다. 주의해야할 점은 인물이 멀 경우 눈이나 얼굴이 잘 안나올 수 있다. 적절한 줌도 추천된다.
프리미엄 프로에서는 [Sequence] > [Sequence Settings]에서 프레임 사이즈와 Timebase를 조절할 수 있고, 영상 클립의 오른쪽 클릭 후 Scale to Frame Size로 크기를 자동 조절하거나, Effect control에서 Position이나 Scale을 추가로 조절할 수 있다.

2. 영상에서 프레임 별로 이미지를 추출한다.
프리미엄 프로에서는 [File] > [Export] > [Media...] > Format을 PNG로 하여 Export 버튼을 누르면 된다. 그러면 프레임 별로 PNG 파일이 생성된 것을 확인할 수 있다.

3. 추출된 이미지 중 하나를 애니메이션 스타일로 변환한다.
추출된 이미지 중 하나에 대해서 img2img 에서 ControlNet을 이용하여 애니메이션 스타일로 변환한다.
- 주로 animeLike25D 모델이 사용되는 느낌이었다. 해당 모델은 low Denoising 값에서 실제 사람을 애니메이션 캐릭터로 잘 변환해준다고 한다. 아래는 링크인데 해당 모델이 맞는지는 확실하지 않다. 이 모델의 경우 세팅은 CFG value: 7, Denoising strength: 0.25, sampling steps: 25로 했다고 한다.
https://huggingface.co/stb/animelike2d/blob/main/animelike25D_animelike25DV11Pruned.safetensors - ControlNet은 네 가지를 썼다는 사람도 있고, open pose와 depth 두 개를 썼다는 사람도 있다. 어떤 사람은 canny만을 사용하였다 (Canny low threshold와 Canny high threshold를 모두 75로 두고 하였다. 값을 낮출수록 precise shape를 얻지만 consistency를 얻기는 어렵다고 한다).
아래 이미지는 아래 세팅을 통해 변환하였다.
masterpiece, best quality, 1boy, detailed eyes
Negative prompt: (worst quality, low quality:1.4)
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2510436645, Face restoration: CodeFormer, Size: 512x768, Model: model, Denoising strength: 0.1,
ControlNet-0 Enabled: True, ControlNet-0 Module: canny, ControlNet-0 Model: control_canny-fp16 [e3fe7712], ControlNet-0 Weight: 1, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1 (Threshold는 모두 150),
ControlNet-1 Enabled: True, ControlNet-1 Module: depth, ControlNet-1 Model: control_depth-fp16 [400750f6], ControlNet-1 Weight: 1, ControlNet-1 Guidance Start: 0, ControlNet-1 Guidance End: 1,
ControlNet-2 Enabled: True, ControlNet-2 Module: openpose, ControlNet-2 Model: control_openpose-fp16 [9ca67cc5], ControlNet-2 Weight: 1, ControlNet-2 Guidance Start: 0, ControlNet-2 Guidance End: 1


좋은 결과물을 얻게 되면 같은 세팅과 시드로 다른 프레임에 대해서 테스트를 추가로 해볼 수 있다.
3. 같은 세팅과 시드로 모든 이미지를 변환한다.
같은 세팅과 시드로 img2img의 Batch를 통해 모든 프레임을 변환한다.

4. 프리미어 프로로 이미지를 불러와서 다시 영상으로 만든다.
사진을 불러온 후 타임라인에 넣고, 오른쪽 클릭, Speed/Duration을 클릭한다.
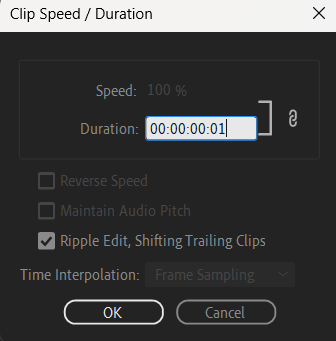
한 프레임의 시간을 Duration으로 잡기 위해서 Duration을 00:00:00:01로 설정한다 (참고로 만약 위 영상이 30 FPS라면 00:00:00:30이 00:00:01:00이 된다).
오디오를 다시 입혀주고, 영상을 export한다.
완성된 영상: https://www.youtube.com/shorts/Ebju0fxsIWM (하지만 영상에서 얼굴이 작아서 그런지, 종종 얼굴이 잘 변환되지 않은 프레임이 몇몇 있었다)
원본 영상: Video by cottonbro studio (https://www.pexels.com/video/hip-hop-dancing-2795746/)
참고 사항
혹은 Premiere Pro가 아니라 After Effects에서 비디오를 불러오고, 인물과 배경을 각각 분리한 후 위 과정을 거쳐서 이들을 합치면 더 consistent한 비디오를 만들 수 있다고 한다.
(참고 자료: https://www.youtube.com/watch?v=aA1AjH7meTA&t=8s, After Effects에서 원본 영상(장면, footage)을 Roto Brush Tool로 rotoscoping하면 인물만 따로 분리할 수 있다. 하지만 일일이 프레임마다 수정 작업을 거쳐야해서 꽤 시간이 걸리는 작업으로 보였다.)
또한 Topaz AI upscaler를 이용하면 더 나은 화질과 frame interpolation을 얻을 수 있다고 한다.
한편, 저작권과 관련하여 저작권자는 저작물의 형식 및 내용에 대해 동일성을 유지할 권리를 가지므로 허락 없이 변경하면 동일성유지권이 침해될 수 있다. 그 외에도 복제권, 공중송신권, 2차적저작물작성권 등을 침해할 수 있다. 침해를 하지 않으려면 보도의 목적이거나, 원작에 더한 새로운 가치를 창출해야 한다고 한다. 그래서 변환할 원본 영상을 선택할 때 주의할 필요가 있을 것 같았다.
(https://www.youtube.com/watch?v=adHRATRSbYA)
특정 키 프레임 변환 후 EbSynth 사용
참고로 위 방법이 아니라 ControlNet과 EbSynth를 활용하여 영상을 바꿀 수도 있다.
ControlNet은 input의 형태를 따라가면서 추가적인 변형이 가능하도록 해주고, EbSynth는 기존 영상에서 특정 프레임 몇 장을 뽑아 (보통은 처음과 마지막, 특징적인 프레임 등) 변형한 사진을 가지고, 해당 사진 느낌으로 영상을 바꿀 수 있게 해준다 (https://namu.wiki/w/Ebsynth, 새로 나온 기술은 아니고 어도비 측에서 이전에 개발한 기술). 아래에서 EbSynth 관련 내용을 확인할 수 있다.
https://www.youtube.com/watch?v=n5DZFbQTOus&t=59s
그래서 기존 영상에서 사진을 뽑아서 ControlNet으로 새로운 사진을 만들고, 이를 Ebsynth를 이용해서 동영상을 제작하면 변형된 영상을 매끄럽게 확인해볼 수 있다.
관련 참고 자료들
- https://www.reddit.com/r/StableDiffusion/comments/11oqed2/froglog_realisticvision_controlnet_ebsynth/
- https://www.reddit.com/r/StableDiffusion/comments/11zeb17/tips_for_temporal_stability_while_changing_the/
- https://www.reddit.com/r/StableDiffusion/comments/12o8qm3/finally_installed_the_newer_controlnet_models_a/
위 참고 자료 내용을 요약하면 다음과 같다.
- 영상에서 프레임을 뽑는다.
- 4개나 9개의 프레임(key frame)을 골라서 2X2 혹은 3X3 그리드로 합친다.
- 합쳐진 그림을 ControlNet을 이용하여 변형한다 (HED나 Canny 사용).
- 합쳐진 그림을 다시 프레임으로 나누고, EbSynth를 이용하여 영상을 변형한다.
이 방법이 처음 방법보다 영상이 튀는 느낌이 훨씬 적었다.
위 방법을 쉽게 할 수 있는 extension이 Temporal Kit로, 아래 영상에서 해당 내용에 대해 잘 설명되어 있다. Temporal Kit을 사용하면 자동으로 key frame을 뽑아 2X2나 3X3의 그리드 형태로 만들어주며, 해당 파일이 들어있는 폴더를 img2img batch에서 변환하고, EbSynth에서 나머지 프레임을 바꿔주면 부드러운 영상이 제작된다.
https://www.youtube.com/watch?v=rlfhv0gRAF4
그 외 방법들
아래 레딧 글에서는 여러 가지 플러그인과 프로그램을 사용하여 영상이 튀는 것을 방지했다.
https://www.reddit.com/r/StableDiffusion/comments/12y7z7i/tiktok_girls_hot_dancing/
r/StableDiffusion on Reddit: The secret to REALLY easy videos in A1111 (easier than you think)
Posted by u/Baaoh - 257 votes and 57 comments
www.reddit.com
- mov2mov extension 설치 및 실행 (https://github.com/Scholar01/sd-webui-mov2mov.git). 이는 동영상을 받아서 프레임 별로 img2img2를 돌린 후 동영상으로 합쳐서 준다.
- FILM(https://github.com/google-research/frame-interpolation)이나 Flowframes(https://nmkd.itch.io/flowframes)를 사용하여 보완. 이들은 두 사진이 있을 때 그 사이의 사진들을 생성해주는 프로그램이다. 그래서 프레임이 낮은 영상을 높은 프레임의 영상으로 바꿀 수 있다 (뚝뚝 끊기는 영상을 자연스럽게 이어지는 영상으로)
- Topaz video AI로 영상을 부드럽게 변환. 위와 마찬가지로 프레임을 높이거나, 화질을 높일 수 있다.
참고 영상들
1. 나이를 굉장히 젊게 만든 영상: SD+ControlNet+EbSynth+Fusion
r/StableDiffusion on Reddit: Stable Diffusion Deepfake - De-Aged Harrison Ford | SD+ControlNet+EbSynth+Fusion
Posted by u/howdoyouspellnewyork - 4,505 votes and 285 comments
www.reddit.com
2. 완전히 다른 캐릭터로 변경한 영상: img2img batch와 포토샵을 사용하였다. ControlNet preprocessor로는 canny, depth, softedge을 사용하였으며, 하나의 옷차림으로만 학습된 lora를 썼기 때문에 옷차림이 유지되는 것으로 보인다.
r/StableDiffusion on Reddit: My attempt at changing the subject to Himiko Toga
Posted by u/BryGuy_ai - 232 votes and 25 comments
www.reddit.com
3. 짧은 애니메이션 영상: 블랜더로 먼저 캐릭터 영상을 만든 후, img2img batch로 캐릭터를 2D 이미지로 변환하고 Ebsynth를 썼다고 한다. 그 이후에 벚꽃 배경이나 효과 등은 영상 편집 시 삽입하였다.
r/StableDiffusion on Reddit: Cherry Blossoms - Animation with EbSynth, ControlNet
Posted by u/mokai83 - 232 votes and 13 comments
www.reddit.com
4. 서로 다른 느낌의 영상으로 변환: 한 영상을 각각 다른 느낌으로 변환한 영상으로, ControlNet 6개 preprocessors를 사용하여 만들었다고 한다.
https://www.reddit.com/r/StableDiffusion/comments/13j9a0x/4_elements_ai_video_transformation/
r/StableDiffusion on Reddit: 4 ELEMENTS - AI video transformation
Posted by u/3Dave_ - 287 votes and 35 comments
www.reddit.com
5. 픽셀 GIF 파일을 실사 느낌으로 변환한 자료: 프레임을 더 높여서 편집해도 좋을 것 같았다.
r/StableDiffusion on Reddit: Quick Animation test of my remaster of Mortal Kombat 1 ( not the final sprites )
Posted by u/Many-Ad-6225 - 1,748 votes and 113 comments
www.reddit.com
6. 굉장히 튀는 것이 적은 영상인데, Roop를 활용한 영상으로 추측되고 있다.
https://www.reddit.com/r/StableDiffusion/comments/150fxok/man_to_woman_using_img2img/
From the StableDiffusion community on Reddit: Man to woman using img2img
Explore this post and more from the StableDiffusion community
www.reddit.com
유튜브 채널도 놀러오세요 😊 좋아요·구독 감사합니다 🥹


'AI Image > News & Tips' 카테고리의 다른 글
| [Stable Diffusion] Web UI의 기능들 정리 (0) | 2023.04.03 |
|---|---|
| [Stable Diffusion] LoopWave script와 FILM을 통한 영상 생성 (0) | 2023.04.03 |
| [Web UI] Web UI 사용 꿀팁 모음 (0) | 2023.04.01 |
| [Stable Diffusion] 얼굴을 재보정해주는 ddetailer (0) | 2023.03.26 |
| [NovelAI] 그림의 퀄리티를 높이는 매직 태그 (0) | 2023.03.26 |